
Quality Assurance
We would like to be able to make definitive statements about our software. If we’re to do that, there has to be a mechanism that runs our tests on every version of the software.
This is automated testing, but somewhere in the 2010s continuous integration (“CI”) tools (tools for doing long-running integration tests on a server separate from the developer’s workstation) took over the whole automated testing world. So now we use the term “CI” for all automated testing performed elsewhere than the developer’s workstation.
There are a million CI systems out there. They all basically have the same shape these days:
- There’s a server running on a remote machine that “knows about” a set of repositories, and has some sort of access credentials to them;
- The server monitors those repositories, either by repeated scanning, or repository callback hooks, to find per-repository configuration;
- The per-repository configuration, which is script-like, enumerates a set of test commands and the associated resources required to run them (e.g. operating system, AWS instance type, whatever…); it usually also specifies a set of branches to monitor, and a set of events (merges, pull requests, periodic timers, …) to watch on those branches;
- When a relevant trigger event occurs, the relevant resources are awaited or provisioned, the configured procedure is run, and a pass/fail result is extracted; some number of collateral artifacts (logs, output data, installable packages) may also be collected.
- Result status is pushed to various locations and notification mechanisms such as email, slack, red alarm flair on web pages, etc.
Because these systems are all basically the same, I have chosen to model the easy and cheap one: Github Actions. Eventually I may want to migrate off of github, at which point I will need a new CI system (probably self-hosted) but Actions is simple enough (a couple of trivial yaml files) that I’m not building in much vendor-lock by using it.
Important Principles
It is easy for CI to become extremely maddening, and in particular very hard to debug. If something fails on an ephemeral cloud machine, and returns only a limited set of artifacts, it can be quite hard to figure out what went wrong. To mitigate this, we follow some self-imposed rules:
- Traceability: Every CI run must be able to be referred to by a unique identifier such as a persistent URL.
- Reproducibility: Any CI run must be very precisely reproducible on a
machine under a developer’s control.
- (This is almost, but not quite, a determinism requirement. The test
performed in CI might have nondeterministic inputs, so long as those
are recorded for deterministic reproduction. So CI can choose a random
seed nondeterministically, for instance, so long as it’s recorded.)
- (But really, determinism is the gold standard here.)
- There are cases in which nondeterministic CI is unavoidable or outright desirable, and we will get to those later. However as a general rule, if you think that you are in one of those cases, no you aren’t.
- (This is almost, but not quite, a determinism requirement. The test
performed in CI might have nondeterministic inputs, so long as those
are recorded for deterministic reproduction. So CI can choose a random
seed nondeterministically, for instance, so long as it’s recorded.)
- Obviousness: The modal CI-detected problem has never happened before, so the average CI debugging process happens when you don’t remember how it works. So CI output must be extremely self-explanatory and the tracing and reproduction procedures must be obvious.
CI is one of the areas where it is easiest for experts to build a system that only they themselves can use correctly. THIS IS AN ORGANIZATIONALLY FATAL FAILURE MODE. If you create a system where the author’s knowledge, skills, or stored credentials are required for correct operation, and where the absence of those is detected only long after it has occurred, then you can sleep-walk off of a cliff.
Hidden Gotcha
The “Reproducibility” item above doesn’t quite match Github Actions' defaults: If you use any autogenerated actions template, Github specifies:
runs-on: ubuntu-latest
and so it is hard for another build to reproduce the exact platform, which can have changed out from under you. Some amount of platform shear like this is inevitable when you are using a third-party hosted solution – after all, they will want to apply security patches without asking your permission. If we were a real organization we’d use a self-hosted builder.
So we slightly constrain the ubuntu version but accept that the specific platform will be not-quite-reproducible for now.
This PR
This PR adds two top-level scripts:
precheckcorresponds to what must always be true at every revision in the repository; it is meant for local testing, and currently runs unit and integration tests.- By running
prechecklocally, a developer can be confident that their PR will pass “premerge CI” (see below).
- By running
validatecorresponds to what should be true of most revisions, and must be true of all releases. It runs all of the tests, even potentially expensive system tests.- A developer may need to get access to a supported platform to run this script, which they may not have.
It adds two CI workflows:
precheckrunsprecheck.shon a PR and must pass before that PR is merged.validaterunsvalidate.shonmain, which populates the red flair on the github project page.
In Github, under “branch protections”, we can in theory set it to require
premerge at this point. In practice you have to wait several hours because
Github is bad at being Github.
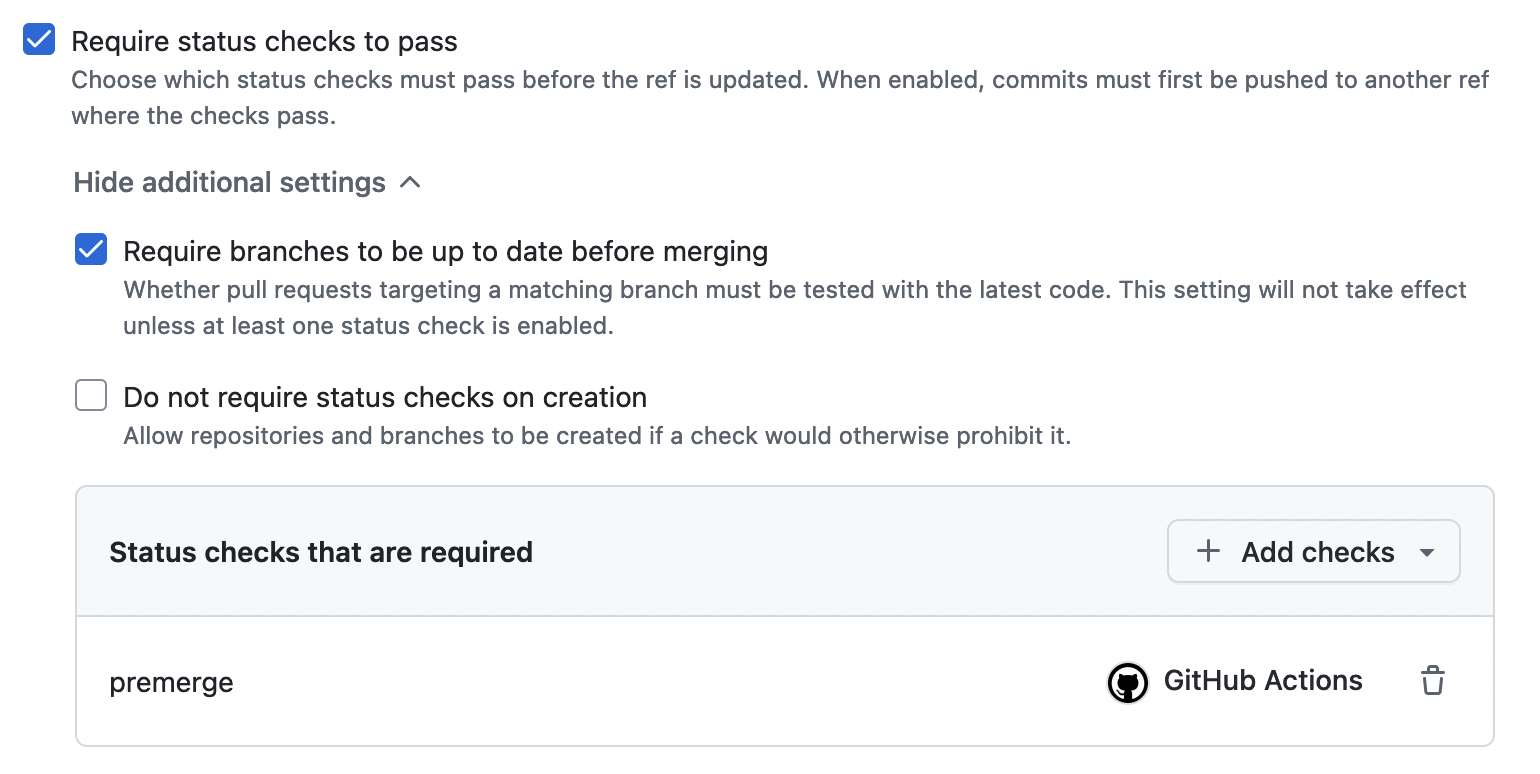
Of course all of this assumes that we’re using a PR-based workflow, which secretly I have not been up to this point. Generally speaking, CI support is the moment when a PR-based workflow becomes necessary (and, equivalently, when scalable collaboration becomes possible). So as long as I’m in the branch protection dialog, I’m turning that on as well.
This blog post corresponds to repository state post_04
Lunar metadata: This is an expansion phase; the scope of the codebase grows.