
Aversion
Pseudoscientific bullshit warning: This piece is an extended analogy based on an at best impressionistic view of a small quantity of research that honestly I barely skimmed.
Where are we?
So I missed a week or two here. There’s a few reasons for that, all of them perfectly good and sensible, but let’s talk about one of the big reasons for missing, which is aversion. Some times a task, activity, entity, artifact just becomes an allergen to attention. It’s different for different people (and some of those differences are diagnostic of ADHD so maybe get that checked), but it often looks something like this:
- You look at the task and immediately think of something more important to do. Perhaps this happens so quickly that you have no recollection of ever having thought about the task, and later wonder why you didn’t remember to think about the task at all.
- Looking at the task fills you with unaccountable rage. The more you look at it the worse your mental equilibrium gets. You lash out at someone around you, for no discernible reason.
- The task looks more and more insurmountable; any thoughts of how to solve it seem laughably inadequate. It becomes a dark hole of despair; look away, look away!
- You keep forgetting that the task exists. When you see it on a task board or a schedule you make a vague commitment to do it but by ten minutes later you have no recollection. Perhaps your mind has anticipated the effects earlier in this list and leapt in front of the bullet to protect you.
- The task is in some sense objectively awful (e.g. for me, here, now, “writing atomicity integration tests sucks so much!") and its awfulness makes it awkward to fit into your available time, mental resources, or attention. Every time it doesn’t fit, the task seems slightly larger; over time it comes to seem endless.
I cannot tell you how to fix these problems. I believe that we all have them all at times, and each must find our own ways to address them unique to the topology of each particular mind.
But I do have thoughts.
A Theory of Injury
Think of an athlete making an acute angle turn – a hairpin change of direction, perhaps to evade an opponent’s cover or to receive a passed ball without revealing its direction.
Every last kilogram-meter-per-second of forward momentum must be thrust away, deaccessioned to air or earth. In doing so every single corresponding joule of energy must be stored for a moment, then in the next moment retrieved. The ankle and knee unlock and tighten; the hip rotates and sinks; the immense cords of the thigh pick just the right tension to time their spring extension and compression to the rhythm of the action.
As this symphony of flexions, rotations, and tensions proceeds, lateral stabilizing muscles tighten far beyond comfortable limits to fix each joint to a single dimension of rotation – muscles that play no role in the momenta and energies flowing back and forth, but which hold the actions of bones to the correct plane of motion.
And if any part of this stabilization goes wrong, a hip slips too far and a knee rotates out and an ankle supinates and that same path of momentum and energy flow becomes a river of injury instead as the full weight of the body twists each joint in turn out of plan and wrecks it. To avoid a cascade of disaster, each joint either locks or goes slack depending on evolution’s best estimate of its vulnerability. Collapsing to the ground in pain is the best outcome, and the body delivers.
Considerable research into sports injuries show that despite the impossible advances of medicine, their rate has not declined: Sporting, for whatever reason (illegible to me, I’m afraid – I don’t get sports) will simply consume every advance of capacity as an advance in the frontier of performance. Like any optimizer, its hunger is insatiable until a countervailing goal stabilizes it.
That same research, as I understand it, tells us that the best predictor of avoiding sports injury is the practice of multiple sports; athletes who specialized on one sport too early in their careers will suffer a higher rate of injury for the rest of their lives. And this should not surprise us: The muscles that prevent injury – those stabilizers around the joints that keep them pointed the right way – are after all not the ones that go higher, faster, stronger toward the apex of sporting apotheosis.
What this has to do with us
Of course the body’s muscles are absolute wimps compared to the regret machine in our heads. Constituting 2% of your body mass (assuming that you, the reader are human; if you are a machine the point here is a bit more subtle but you can probably work it out as an analogy for gradient collapse), the brain burns ten times its share of calories, clocking north of 20% of your metabolic load.
And not that healthy stored-fat metabolism either – the brain takes direct access to the glucose taps and counts on the rest of your body to keep up. Using a brain is comically unhealthy for anything much thinkier than an anole.
Under these circumstances it would be madly odd if our mental health were not similarly vulnerable as our physical health, and if those of us whose work will consume every available cognit1 in a mad festival of optimization did not suffer the equivalent of sporting injuries, and if our mental constitutions did not rely on cognitive stabilizers just like that poor overtorqued knee joint, acting at right angles to the axis of thought, to keep us sane.
Equally, we experience freezing and collapse of our mental joints as we overload them to minimize lasting damage.
And so I hypothesize that it is equally likely that we must exercise our minds on other sports – find other directions and diversions to train up those right-angle muscles that don’t do the heavy lifting of cognition. I do believe that meditating in the morning and working the crossword in the afternoon is injury-preventive training, that my coworker knitting during a meeting is in fact stretching and hydrating, and that the junior engineer building a wall of coke cans is actually…
…no actually, I can’t continue that analogy that far, he’s just self-harming.
I also believe that task aversion is an injury prevention response by the brain, a sign that my mind knows that I have not sufficiently warmed up for this exercise and I should probably pick a different load to carry today.
This is why I am skeptical of purely attitudinal solutions to aversion. It’s baked into the condition of the world. Our minds are finite things with beginnings and endings, subject as the Suttas say to birth and defilement. To have the knowledge of failure is to feel the desire to turn away from harm. The power of positive thinking isn’t really in that same league, metaphysically.
Rather, when we feel task aversion we must train those right-angle muscles.
(I also believe that this is what my intellectual nemesis/obsession Dijkstra was actually noticing when he saw that the best programmers were fond of puns in their native languages: Survivorship bias.)
This is especially a concern when mentoring
If you’re mentoring someone and they’re having task aversion, it’s pretty noticeable but hard to act on.
In my experience, don’t push on it, and definitely don’t tell someone to get better at time management or better document their estimates or whatever. It’s much better to reassign the task to someone else and assign a very different task instead. Prescribing vacation days might also be sensible but we can’t actually write “touch grass” in a github ticket.
Telling someone to do a round of estimating and tasking out future tasks can be a good way to get them unstuck on their current task. It’s also virtuous in its own right.
A note about moral injury
There is one other sort of injury that I would be remiss not to mention. The military – who know a thing or two about injury both as keen observers and actual enthusiasts – characterize a concept of “moral injury”. That’s both “moral” in the sense of ethics and “morale” in the sense of will to succeed, but the two concepts are understood as rhyming in their discourse.
Moral injury is the cluster of symptoms that follow from witnessing, allowing, or engaging in wrongful acts. Those symptoms are wide and varied, from depression and obsession to aggression and thrill-seeking to nihilism2 and self-harm. Task aversion fits naturally in this category.
So if you’re experiencing task aversion you should definitely check in with yourself ethically. Are you unmotivated because the task is bad, or the task seems similar to tasks that were bad in the past, or the task reminds you of something? If this is the case, no other way of addressing it is going to help, and you need to go for a walk and clarify how you think about what you are doing.
Moral injury is also part of the mental immune system that makes us allergic to both dangerous and harmless-but-sus intentions. It simply cannot be ignored, and requires real attention and respect. Don’t keep working the injured limb! Rest it for a while! Heat and stretch!
We too often forget that the ethical context of our work makes itself present in everything we do; there is no means-ends distinction in the world.
–
Today’s commit
There is no commit this week because I’m temporarily stuck. Oh well. Instead I’m going to experiment with RSS synchronization to the fediverse.
Lunarism
Each of these posts has a remark about “lunar metadata.” This was an idea first proposed to me in the early 2000s (I cannot recall which coworker to credit with this… Heather Wakefield, perhaps?) that we should regard software development as proceeding in phases.
The theoretical principle here, oddly, is down to cybernetics.
If we want to hold some variable at a target value, and it is influenced by some input, control theory tells us we ought to start out by pushing back on any deviations with the first derivative of their relationship. If x is one unit too high, and increasing y by one unit increases x by two, apply negative one half y and see what happens. In this way we “attach a spring” between inputs and outputs, keeping everything in line.
But if the relationship between x and y has even the slightest bit of lag, or is in some interesting way other than linear, this synthetic spring will get bouncy. The greater the lag, or the greater the higher-order derivatives (call them “stiffness” if you like) the more that madness will creep in.
For any attempt to control such a system there is a slowest possible change that you can counteract (usually defined by limits on how finely you can measure and how hard you can push the system) and a fastest possible change that you can counteract (usually defined by how quickly you can measure and adjust control) and the difference between these is your “control bandwidth”. When we build layered systems we generally want the highest control bandwidth in the lowest levels, and the lowest control bandwidth in the highest level.
When we don’t have enough control bandwidth, our systems blow up or oscillate wildly.
Which is a problem for us.
Whatever we are trying to accomplish with software, the fuck around / find out loop is annoyingly long. In control terms the control bandwidth of software development is really crap. And where is it most crap? In the code we are least able to control. What is the code we are least able to control? The code that is most load bearing, where any adjustment can wreck the world.
We can of course take countermeasures. Broad, intensional testing of low-level code lets us treat its behaviour rather than its embodiment as normative, freeing us up change it with higher frequency. Skillfull, patient, and ethical development practices allow us to better anticipate the results of our changes and to be attentive to the parts of our code where slow degradation might otherwise go unnoticed.
But in the end we are always working at the edges of controllability: If software development reliably produces the results we intend, we do more of it, until it doesn’t; some combination of a Peter Principle and survivorship bias guarantees that in a complex software system nearly every bit of the codebase is collapsing, exploding, or oscillating wildly, because if it weren’t already we would make it so.
Some failures are better than others.
So as long as we are living in e^kx what k do we want? Positive k means explosion; we don’t want that. Small k is collapse, also no good since the whole principle is that people do want changes. Imaginary k means oscillation – things can change but they ultimately roll back around. That sounds tastier.
Big imaginary ks mean high frequencies; we sure would like to do things fast! Can we do that? Well that gets back to control bandwidth – we have to put that imaginary component in the range of our control.
And so we can say – the whole ballgame is control bandwidth. Can we anticipate and detect slow changes; can we quickly match our control to a quickly spiraling project; can we time our interventions to not worsen a pathological explosion?
When we train a junior engineer, we teach them how to push on the code, how to push hard, how to respond quickly, how to correct. It is a discipline of sudden extremes and fast feedback. These are the skills of the linear mode, of seeing where you want things to be and pushing in that direction until they are there.
As we become senior we must shift instead to grasping the intertemporal, oscillatory mode; we anticipate how the code changes, how its uses and intents change, and focus instead of writing the code that someone else will discover themselves needing in the future, positioned where they will be looking at the moment they realized they need it.
Lunar Process
Hence the lunar metaphor. We want our work to by cyclic, so that we can match our cycles of work to the cycles of code and then adjust our cycles to lead or lag those of the code to push and pull its phase and frequency. This will not bring our development process to a perfectly damped static equilibrium, but a dynamic equilibrium of converging oscillation.
The simplest cycle of practice I have found is to alternate expansion and contraction. These are kinds of PRs we know how to write! Here are the definitions I am currently using:
- An expansion PR straightforward expansion. The code does more than it did yesterday. There are new API endpoints, new types and classes, new seams. TODO comments proliferate; functions emerge like mushrooms, novel paths blast into undiscovered functionality territory quite without regard for desire lines. Brainstorming and adding placeholder files are the purest form of expansion.
- A contraction PR consolidates prior expansions. The code does what it did yesterday but with greater clarity, correctness, or performance. It is better supported by tools; TODOs are resolved, functions and types are pruned to match what their use cases have turned out to be. Documentation and design are contraction; behaviour-driven testing (invariant-driven testing co-located with functional documentation) is the purest form.
There are many other sorts of cyclical development, but keeping this form in mind and alternating batches of PRs between them is a useful mental discipline. Asking, “is this an expansion day or a contraction day for this project?” will seldom leave you worse off.
–
Today’s PR expands us into data storage. There’s a lot of trouble brewing there, but today is not the day to explain it. Suffice it to say: We don’t ever want to deal with a filesystem; the right choice is to slap one or two carefully chosen abstractions on and run away. Once we get to perf optimization that will will become very false, but that’s trouble we chose not to borrow right now.
This blog post corresponds to repository state post_09
Lunar metadata: This is an expansion phase; the scope of the codebase grows.
Escape pods
Well then, I suppose we need to talk about escaping.
This is going to be extremely impressionistic because I’m not an historian. Apologies for all the wrong details to follow. It is easy for people of my age – the age of ASCII – to forget that string escaping has usually been complicated and weird. In the ASCII world a byte was a character, a list of characters was a string, and there were two exceptions that you could keep in your head without a worry.
It wasn’t the case before. Before ASCII in the IBM world came EBCDIC, and in EBCDIC most bytes weren’t characters. For a while a byte corresponded to a keyboard entry (a key or key+modifiers) and bytes were as many bits long as it took to do the keyboard; the inevitable proliferation of modifier keys called “buckybits” led to 9-bit and even 12-bit bytes, the reason that standards prefer “octet” to “byte” for clarity.
(I had a former coworker who was fond of making keyboard shortcuts that used weird buckybits – hyper-super-meta-greek-shift-L or what-have-you – that only he could type on his old Symbolics keyboard. Emacs let you do that back in those days.)
Really we have always had ugly strings – we left the state of grace when we left three-finger octal and let no one tell you otherwise.
Now we have unicode and so forth and nobody younger than, say, Return of the Jedi is ever going to think that strings are easy. Easy strings were a temporal island of privilege in a sea of complexity.
How Escaping Work{ed|s}
A string is a list of numbers or numerically indexed tokens chosen from a (usually finite, but see later) set, often called the alphabet. An encoding is way of writing a string in alphabet A1 in different alphabet A2, such that every unique A1 string has a unique A2 string (not necessarily the other way around).
Start with the easiest case. The “invariant subset” of EBCDIC is an alphabet of 162 symbols (give or take). Most of the other possible binary number combinations were omitted for important reasons like “if we punch too many holes in a row on this punchcard the cardboard will tear”. So if you wanted to store a string of EBCDIC symbols in 8-bit RAM, your representation could just be “copy over those binary bits.” A hundred-ish combinations of bits are left over – symbols in 8-bit RAM that don’t correspond to symbols in EBCDIC, so you had plenty of room to put weird control tokens in like “end of string” or “raise a particular electrical connection on your serial port.” Sure there were weird problems like “j” not coming after “i” or people randomly filling in the unused bit combinations with mathematical symbols that you couldn’t represent with punchcards. But other than that … life was good!
Then people got wise to binary, stopped using punch cards, and all heck broke out. ASCII had 127 symbols, and then 128, and then suddenly 256 (this is a lie) and people started to want “character” and “byte” to mean the same thing. You have an alphabet of 256 symbols, you have a computer that works in 8-bit units, and so life sucks. Life sucks because you always need at least one spare representation, and more often two or three, so that you can also encode metadata like “this is the end of the string.”
Because when your encoding of A1-strings to A2-strings has A1 and A2 of equal size, you quickly find out that you didn’t quite get A1 right after all.
There were tricks of course. If you know where a string starts, you can make the first byte be its length. If it’s longer than 256, you can make the second byte be more of its length? Opinions vary. Cleaner: Reserve one byte value as “not a real character” and make that the end-of-string mark. But then, oops, people suddenly have the clever idea of using the end-of-string mark to indicate other things, like the end of strings inside of your strings. Look up the -0 flag to xargs. Cry a bit.
in the final analysis, an encoding must always reserve space either along the length of the encoded string (a “how long is this string” position) or in the width of the alphabets (one or two reserved symbols – usually more). A great programming language war of the past is memorialized in the names: The former is a “Pascal String”; the latter a “C String”. C could actually use both, which is part of why we don’t have Pascal to kick around any more.
So there’s an answer. Instead of reserving a separate symbol for each weird thing you want to do, reserve a symbol for “treat the next symbol as me doing something weird.” Today everyone except haskell and podcast sponsors use backslash for this.
(Old pre-1980 editors used to have modes, usually an “append” mode and an “edit” mode at least. Going between modes was called “escaping” and used the “escape” key. Since keyboard keys and characters were co-extensive, there had to be a way to get the escape key’s character. So the trick to get a literal escape character was called escaping. Or at least that’s how I heard it. I used SuperText back on the Apple 2; it was secretly an Apple port of vi, I think.)
Originally the idea was, “backslash means treat the next character as itself and not as any sort of control command.” So backslash-nul represented nul and not end-of-string. Joy! But nobody wants to type nul (there’s no nul key on your keyboard) so how about backslash-zero? And of course backslash-backslash means backslash so you haven’t actually given up any expressive power. But you can’t just give people that power… there are lots of characters that are inconvenient to type. So backslash-p could be “the number of characters left in the string, expressed as a byte”! And backslash-whitespace could mean “remove all the contiguous whitespace after here” so you can indent your code nicely! And backslash-n could mean “however this machine represents a newline” and backslash-r could mean “the other way of representing a newline that machines other than this one use, those dirty commies.”
Pretty soon you have a whole backslash menagerie. Never give programmers an inch, is the moral here.
Unicode. Dear god.
In the days of EBCDIC, there was a very simple rule: All languages get Roman-alphabet letters plus as many extras as can fit in a line of a punch card. Foreigners had to buy extra-sturdy punch cards because the cards got flimsy if you punched out too many spots. Foreigners with more letters than fit in the 90 or so extra letters left over… nope. Don’t ask. China was still Red China at the time and IBM couldn’t sell very many computers there.
Actually people came up with lots of clever tricks to handle this. TROFF encoding worked like old typewriters where you could write á by writing a-backspace-apostrophe. It’s still used in a few places, naturally.
ASCII rationalized all of this by standardizing to 128 characters that normal people use, one extra bit to use for a checksum (7-o-1 ride-or-die IYKYK, UART 4eva), and then don’t use it for a checksum, use it to hide all the weird foreign things in “upper ASCII.”
Well it turns out that there are foreign languages with more than 128 characters. Don’t sweat the details. You could write a new system where there’s a table of every symbol that has ever been used for human writing, and it has some bytes associated with it, and then some rules for how you can skip bytes that repeat too much. They got the size wrong and had to do it a second time.
The second time they had a simpler rule: Every symbol ever used in human writing (including simplified Chinese, which they messed up the first time) gets a number. A string is a list of numbers. The numbers can be represented in memory or on disk in a bunch of different ways, as long as we agree that it’s a list of numbers – numbers that might be quite large.
I am not going to write an explanation of Unicode 2; lots of people have written those already. “Every character has a story” was a great blog.
Anyway the numbers are all magic. Some of them make the other letters nearby work differently. Some of them change the way that bits and bytes work. Some of them make time run backwards. It’s a funny world.
The important thing is that the old idea of “characters are written as bytes; there are a couple of exceptions but you can write them down” was dead dead dead at this point. Java put the nail in the coffin by saying that you don’t just put user display text in unicode, your program is unicode. Name your variables poop-emoji; it’s fine.
Wait, really?
No, of course not. Unicode programming languages were a catastrophe. Simple questions like “what characters end a comment” imploded into impossible complexity. Nobody could write parsers. It was madness. All of the high-throughput filesystem operations that count numbers of bytes could unknowingly read fractions of a symbol. It’s like nobody ever learned anything from stateful serial protocols and trying to get a serial mouse work with a PS/2 connection, but at epic scale.
However the case for unicode was compelling and people muddled through. The principle remained:
- You write code in some alphabet. Your code has things that aren’t literal strings, so the things you write in your code are not identical to the things they represent.
- So some things in your alphabet have to represent more than one thing. Like quotation marks. Quine Quine Quine Hofstadter Quine Quine.
- So we still need a magical character to “escape” from literal “raw” strings.
Unicode escaping has more edge cases than Triplette Competition Arms. It’s far beyond the realm of what any one person can handle. It’s so bad that as formally specified unicode regular expressions can’t be matched using regular grammars.
But in then end, there are characters, which are numbers, and are different from bytes. Most character numbers aren’t bytes, not all bytes are character numbers, and not all numbers are characters. Some lists of bytes are not strings, and strings turn into lists of bytes via encodings that you have to choose between. And it’s not nice, but it could never have been any other way.(Then emoji happened, and that story will make your hair catch fire. Not here or now.)
Today’s PR will attempt to fix the literal string round trip in the grammar by using a builtin string-escaping feature of nom. It’s not good enough, but it’s just about good enough for now.
Worth noting here is that I’ve added some more aggressive round-trip testing. Handling vacant cases (nans, empty strings, Nones if you are cursed) always introduces opportunities for mischief, so an actual semantic test was in order. Revisit my earlier post on round-trip testing for the gist.
This blog post corresponds to repository state post_08
Lunar metadata: This is a contraction phase; the density of the codebase grows. Note that we have taken multiple contractions in a row; the state of our code is not propitious, and it yearns to grow.
Serialization Formats are not Toys
There was a great video back in the day with that title.
Most of the issues identified in it are long-since fixed, and it didn’t really cover the essentials, but the title is gospel, and it gave a solid flavor of how badly wrong you can go in the simple business of turning structured data into sequential bytes and back.
I estimate without evidence that 90% of as-yet undiscovered security bugs are parser/serializer mismatches, and that’s fine because nobody is actually good enough to reliably identify and exploit them.
However we would be wise to not introduce more.
Representation and Round-Trip
Say we’re writing json. I mean, we will be writing json, but we aren’t now,and won’t be soon, but we will be in this example.
Of course, the on-disk stored json doesn’t match the user-input json, because json is not ordered (RFC 7159). This is the first of what will be many instances where semantically identical objects (objects that would pass their own equality test) have syntactically distinct representations. In some cases these representations are even nondeterministic – for instance objects are often hashed by their pointer address, which differs from run to run.(json has similar issues with floating point numbers; floating point is a wholebag of tragedy that will get its own post or two later)
This is especially acute with set-like datasets, where the absence of ordering and presence of cross-element constraints form a foul sludge of ambiguity. Databases have a lot of those, so we’ll be living in that world.
There are lots of things that we can do to mitigate this – defining hash and equality functions, for instance, greatly reduces the frequency of this problem (but again has problems with floats, which lack total order andequality testing). But the underlying problem is intrinsic: Representationsare not one-to-one with semantics.
This is especially true when we are layering data formats – Unicode has a complex relationship with uniqueness – and when we are doing cross-platform coding, where data types can have different sizes and where collation rules may not always be identical on all supported planets.
In short, trying to enforce rigid data specifications is a fool’s errand for a small organization; even large standards bodies typically fail in some awful edge case or another. You are much, much better off focusing on the invariants of parsing and serialization than on bitwise-identical objects and representations.
Because of this it is very important that we say ahead of time exactly what we require of a representation – that we call our shots.
Eight ball, corner pocket
I’m no mathematician, even less so a computational linguist, so some details below are wrong.
The minimal requirements of a representation are:
- Total Serializability: Every semantically valid object is representable, without exception.
- Unique Serialization: If two objects have the same serialized form, they are semantically equal.
This implies:
- Unique Parsing: Every representation either represents a single semantically unique object or else is an error.
If a representation meets these properties, we have the corollary:
- Semantic Round Trip: The parse of the serialization of an object is semantically equal to the original object.
Running the table
In some cases, we have a canonical serialization of an object. A representation is canonical if:
- Canonicity: Every serialization of a semantically equal object is identical.
If we have a canonical serialization, then we obtain two corollaries:
- Syntactic Round Trip: The canonical serialization of an object, when parsed and re-serialized, gives the original serialization.
- Double Round Trip: For any data, if you apply the sequence parse, serialize, parse, serialize then either the first parse is an error or the two serialize actions return the same result.
Each of the properties above is a hint as to a category of testing that we can pursue. I have a personal fondness for the semantic round trip as a test, I know other experienced engineers who have different preferences, but most folks seem to quickly develop a habit of preferring one of these as their default procedure for testing a format.
This PR
This PR backfills reasonably sound test coverage around the previous PR’s parser example. Unsurprisingly it finds a whole bunch of problems, and fixes them.
It’s worth a look at the special cases in the Float case. Floating point numbers'
human-oriented serializations are not 1:1 on floats, and NaN != NaN, to start with.
Both of these can be worked around (using Debug instead of Display as the base
of serialization; special-casing the comparison). There are further issues with NaN
being a category of values rather than a single unique value that will have to wait for
later.
However string parsing and serialization is too complex to finish in this PR, so its test gets an xfail – it’s the right test code but it can’t pass as the code is currently written. In such cases it’s best to write the test and flip its sense to expect failure; that keeps the test code live for when you need it next.
This blog post corresponds to repository state post_07
Lunar metadata: This is a contraction phase; the density of the codebase grows.
Starting Our Engine
Okay, time to begin in earnest. The simplest entity that exists at each of the front, middle, and back-end is the literal – a literal representation of data.
I’ll get to data model issues later, but for now we are going to start with json as our data model because, frankly, every system these days ends up needing json support somewhere. We are going to need more types than json supports (we’ll need a set type and a special case of sets, the relation type; eventually we’ll also want some gnarlier things like elias-encoded bignums, tensors, gensyms, and atoms) but we start here.
So for our first thread through the system, we say that the front end has a
real parser (because it is meant to have human-friendly features); the middle
end uses vanilla Vector and HashMap representation of that data
(eventually we will want less-vanilla conctree lists, and maybe some sort of
headwords list); the back end will store that data back as something dumb (in
the near term json, a format simple enough that it doesn’t need a “real”
parser).
Obviously this is useless; that’s fine, we’re not trying to be useful yet.
Never write your own parser
If you have classical CS training, you spent a chunk of time on computational grammars, LR(1) and LALR and maybe if you are a young person PackRat or something. And as part of this training you had to write a parser, or a parser-lexer stack, or a semantic actions interpreter, or something.
Due to your level of experience at this point in your career you have met Zalgo at least once, and have at least some vague notion that the horror of that encounter had something to do with the Chomsky hierarchy. Possibly you know one or more jokes about Nim Chimpsky, or clever facts like that regular expressions are not themselves a regular grammar that seemed much more interesting when you were in an atmosphere with a measurable THC1 content.
In short, you are intellectually qualified to write a parser. DO NOT DO THIS THING.
The point of learning to write a parser was never to write parsers. Smart, neurologically Lovecraftian individuals have written parser generators and parser combinators so that those of us whose neural spices come in “medium verbal” or milder don’t have to.
The point of learning how to write a parser is that it is the only way to understand parser error messages. When a parser generator tells you that you have a serial repetition ambiguity or something, your experience writing a parser will activate a long-dormant neuron that will tell you, oh, that’s the thing that happens because order of operations, or maybe that’s the thing that order of operations happens because of, or something, and thereby you will save yourself from a level of frustration typically associated with snapping and driving an armored bulldozer over your neighbor’s oleaceae forsythiae.
Every programming language that doesn’t suck has a parser generator or (more modernly) parser combinator or (if they’re kinky) a parser expression grammar library of which everyone says, “oh, just use that thing, even though its authors are scary and make bizarre lifestyle and/or build system choices.” Use that one.
Rust has not quite reached that level of maturity, but it’s closing in on it:
serde is overwhelmingly canonical for serialization/deserialization, and
nom has about twice as many users as its nearest competitor for parser
generation.
We will use nom for now, and although we won’t need sophisticated
deserialization for some time we’ll plan to use serde when the time comes.
One small complexity appears instantly: nom changes its API regularly,
including changing the return types of existing functions. So we need to
version-pin nom. For the moment we’ll just pin its major version and hope
that it respects semver.
cargo add nom@~8 serde
A brief note
It is a depressingly common convention in query languages that their output
grammars are not in their input grammars; for instance, the result of an SQL
query is typically not valid SQL. There’s a (bad) reason for this, which I’ll
probably get to when I get on my query language soapbox in a later post; for
now understand that that’s why I’m not concerned about nom’s lack of
serialization.
We will pay a large price for this later, but we can’t avoid it.
This PR
Introduces serde and nom into the codebase around a trivial tagged union
of literals. No new or interesting system-level behaviour.
This PR is considerably more than 50 lines, so it certainly contains serious defects, as we will see in the next post. I have deliberately run implementation a bit ahead of testing and comments for illustrative purposes, so the code quality at this revision is somewhat poor.
This blog post corresponds to repository state post_06
Lunar metadata: This is an expansion phase; the scope of the codebase grows.
-
Note for modern readers: “THC” is the chemical people used to recover from staring into the NP-abyss after LSD-25 went out of fashion but before spironolactone and fursuits became widely available. ↩︎
Systems Programming
How do we define systems programming?
Wikipedia and friends will tell you that the term “Systems Programming” refers to software that reaches low-level components of the technology stack in order to enable other software to be more capable and performant. And that’s true as far as it goes, but it doesn’t sing.
I would say, rather: Systems programming is when we enable users to imagine that a computer is something other than a computer.
Consider the four classic systems programming examples: Operating system, compiler, database, network protocol. Each of these presents its users with an imaginary, simpler computer. The compiler, for instance, lets you imagine that computers have structured data and polymorphism and lists and things, even though we know that they only have flat arrays of bytes. A network protocol lets you imagine that things like streams exist, or that your NIC talks IP and that IP networks make connections, or that datagrams arrive error-free or not at all.
(Of course we also work in the realm of imagination. When I do systems programming I make transistors do backflips for me even though I got a C in microelectronics, because a microprocessor presents me with an imaginary view of its basquillions of bipolar junctions and metal oxide tunneling whatnots. This is the essence of computer engineering: Make simplified models of things work as if they were real.)
By allowing users to work in this realm of imagination, we make them more capable, we make their code less error-prone, we make their code make sense. We leverage their fifty correct lines of code per day to fifty better, more powerful, more graceful lines. Fifty lines of python today can do more than the menagerie of odd geniuses at Data General could do in a year.
I like databases because they touch on all of the flavors of systems engineering. Good databases have optimizing transpilers in them, and they work operating system filesystem abstractions to the breaking point, and they frequently involve high-throughput IPC that necessarily resembles networking. A good database rings all the bells.
(The downside is that the conventional user-facing interface for a DB is SQL, which is just terrible. Because this project is deliberately toy-like, we will simply fix that by not using SQL as our interface. When I am choosing, I do not need to choose terrible things. More on this later.)
Structural Implications
It follows that every systems programming project has at least a front end – the imaginary interface that will bring power and joy to our users – and a back end – the place where this system meets its next lower imaginary.
In practice both of these ends are super irritating. The front end is focused on user tasks, and if we wanted to think about user tasks we would have become users. The back end is focused on banging on imaginary raw metal, and we also are not drummers. Everything cool happens in between – the middle end.
The Middle End
The term “middle end” has not caught on, so we usually use the compiler term “Intermediate Representation” (IR; formally a different thing but colloquialism reigns in this messy realm). In compilers, the IR is where all the fun math happens, the point where the user’s ideas of how a computer works have been stripped down to what they actually want and we get to figure out how to turn that into what will actually happen.
As such, the choice of a good IR is a matter of heavy, heavy theory. If this were a real company rather than Barzai banging on his Das Keyboard, we would employ whole-ass algebraists to do nothing but think brilliant thoughts all day. At one previous company we had an entire team of geniuses who mathed amazing math all day to deliver a 13% speedup every single month forever.
I am not a math super genius, and probably neither are you, so what we do is steal an IR from someone smarter. In the case of databases, this work was done by Cobb, the great database theorist. Cobb tells us that the right IR for a database is Relational Algebra.
We’re going to get into that more – lots more – later. For now, put a pin in it and move on.
Implementation Strategies
For a large system with multiple layers, there is only one way to begin, and that is to build “a thread through the system” (h/t Joe Boykin) – a single example that touches every level.
This should be a controversial statement. We could begin by writing interface design documents, for instance, or detailed specifications, or by implementing each layer one-by-one as a standalone artifact. However those approaches are premature.
In particular: Interface design documents for a long project have the reverse-Conway’s-law effect of dictating organizational structure forever. This will cause your organization to become brittle and hidebound and will tank morale. Don’t commit to any interface until you have a prototype in hand to start looking away from bad ideas.
Implementing parts standalone requires a whole lot of work to reify their interfaces to stand alone, an effort which initially appears to be justified because it improves testability, but which ultimately never actually aligns quite right with the tests you actually want to write.
Both of these approaches are much, much more valuable once you have even the most trivial of prototypes, because the prototype can build proof-in-practice of the architecture – and, more to the point, falsify it.
Yes, AN ARCHITECTURE CAN BE FALSE.
An architecture is an assertion that a system structured thisaway can accomplish an unknown future task describable thataway. Of course that assertion can be false! We don’t even know the future task! It’s a miracle that assertion is ever true!
Your architecture has errors, and the cost of an error in architecture grows at least quadratically over the course of development. So we need to falsify our architecture rapidly and repeatedly.
A “thread through the system” is actually subject to ongoing revision, so it’s more than just a prototype. And it provides a whole lot less than a working system, so it’s a lot less than an MVP. It’s a point of departure for our journey into the realms of imagination. It is a cardboard box that we will imagine into a starship via crayons and scotch tape. It’s a mixed metaphor.
This PR
This PR starts a skeleton of main that we will start to hang parsers off of
to build our first thread.
It brings in our first external, the extensible command line parser clap; we
did this via:
cargo add clap --features derive,cargo
This blog post corresponds to repository state post_05
Lunar metadata: This is a contraction phase; the density of the codebase grows.
Quality Assurance
We would like to be able to make definitive statements about our software. If we’re to do that, there has to be a mechanism that runs our tests on every version of the software.
This is automated testing, but somewhere in the 2010s continuous integration (“CI”) tools (tools for doing long-running integration tests on a server separate from the developer’s workstation) took over the whole automated testing world. So now we use the term “CI” for all automated testing performed elsewhere than the developer’s workstation.
There are a million CI systems out there. They all basically have the same shape these days:
- There’s a server running on a remote machine that “knows about” a set of repositories, and has some sort of access credentials to them;
- The server monitors those repositories, either by repeated scanning, or repository callback hooks, to find per-repository configuration;
- The per-repository configuration, which is script-like, enumerates a set of test commands and the associated resources required to run them (e.g. operating system, AWS instance type, whatever…); it usually also specifies a set of branches to monitor, and a set of events (merges, pull requests, periodic timers, …) to watch on those branches;
- When a relevant trigger event occurs, the relevant resources are awaited or provisioned, the configured procedure is run, and a pass/fail result is extracted; some number of collateral artifacts (logs, output data, installable packages) may also be collected.
- Result status is pushed to various locations and notification mechanisms such as email, slack, red alarm flair on web pages, etc.
Because these systems are all basically the same, I have chosen to model the easy and cheap one: Github Actions. Eventually I may want to migrate off of github, at which point I will need a new CI system (probably self-hosted) but Actions is simple enough (a couple of trivial yaml files) that I’m not building in much vendor-lock by using it.
Important Principles
It is easy for CI to become extremely maddening, and in particular very hard to debug. If something fails on an ephemeral cloud machine, and returns only a limited set of artifacts, it can be quite hard to figure out what went wrong. To mitigate this, we follow some self-imposed rules:
- Traceability: Every CI run must be able to be referred to by a unique identifier such as a persistent URL.
- Reproducibility: Any CI run must be very precisely reproducible on a
machine under a developer’s control.
- (This is almost, but not quite, a determinism requirement. The test
performed in CI might have nondeterministic inputs, so long as those
are recorded for deterministic reproduction. So CI can choose a random
seed nondeterministically, for instance, so long as it’s recorded.)
- (But really, determinism is the gold standard here.)
- There are cases in which nondeterministic CI is unavoidable or outright desirable, and we will get to those later. However as a general rule, if you think that you are in one of those cases, no you aren’t.
- (This is almost, but not quite, a determinism requirement. The test
performed in CI might have nondeterministic inputs, so long as those
are recorded for deterministic reproduction. So CI can choose a random
seed nondeterministically, for instance, so long as it’s recorded.)
- Obviousness: The modal CI-detected problem has never happened before, so the average CI debugging process happens when you don’t remember how it works. So CI output must be extremely self-explanatory and the tracing and reproduction procedures must be obvious.
CI is one of the areas where it is easiest for experts to build a system that only they themselves can use correctly. THIS IS AN ORGANIZATIONALLY FATAL FAILURE MODE. If you create a system where the author’s knowledge, skills, or stored credentials are required for correct operation, and where the absence of those is detected only long after it has occurred, then you can sleep-walk off of a cliff.
Hidden Gotcha
The “Reproducibility” item above doesn’t quite match Github Actions' defaults: If you use any autogenerated actions template, Github specifies:
runs-on: ubuntu-latest
and so it is hard for another build to reproduce the exact platform, which can have changed out from under you. Some amount of platform shear like this is inevitable when you are using a third-party hosted solution – after all, they will want to apply security patches without asking your permission. If we were a real organization we’d use a self-hosted builder.
So we slightly constrain the ubuntu version but accept that the specific platform will be not-quite-reproducible for now.
This PR
This PR adds two top-level scripts:
precheckcorresponds to what must always be true at every revision in the repository; it is meant for local testing, and currently runs unit and integration tests.- By running
prechecklocally, a developer can be confident that their PR will pass “premerge CI” (see below).
- By running
validatecorresponds to what should be true of most revisions, and must be true of all releases. It runs all of the tests, even potentially expensive system tests.- A developer may need to get access to a supported platform to run this script, which they may not have.
It adds two CI workflows:
precheckrunsprecheck.shon a PR and must pass before that PR is merged.validaterunsvalidate.shonmain, which populates the red flair on the github project page.
In Github, under “branch protections”, we can in theory set it to require
premerge at this point. In practice you have to wait several hours because
Github is bad at being Github.
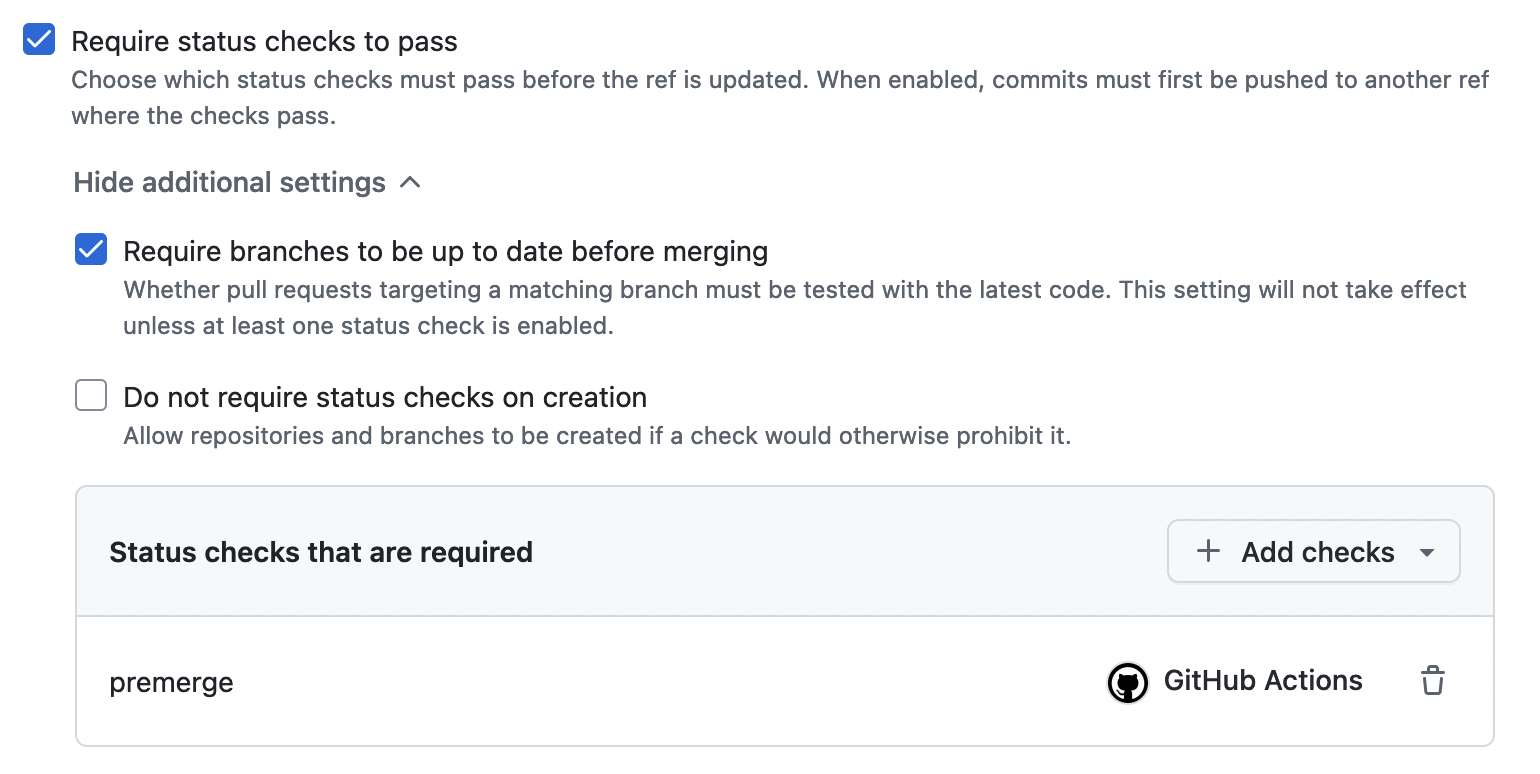
Of course all of this assumes that we’re using a PR-based workflow, which secretly I have not been up to this point. Generally speaking, CI support is the moment when a PR-based workflow becomes necessary (and, equivalently, when scalable collaboration becomes possible). So as long as I’m in the branch protection dialog, I’m turning that on as well.
This blog post corresponds to repository state post_04
Lunar metadata: This is an expansion phase; the scope of the codebase grows.
Inflating the Balloon
Now that cargo init has given us raw materials, it’s time to fill in some
initial proof-of-concept content. In effect we have been given an
deflated balloon – all that we need, but no space inside. It’s time to blow
up the balloon with enough infrastructure that we can “just write code.”
Tests
There are a lot of kinds of tests, but nearly all of them fall into three categories:
- Unit tests test that a single module’s behavior agrees with its
documentation and does not emit surprising errors.
- A special case of unit test is a “smoke test” – a trivial test that a function can be called or an object created and destroyed (also called a “lifecycle test”). Smoke tests are more pedantically categorized as integration tests (e.g. constructability of an object is higher-level than the object’s Liskov-specification) but in the same ways that olives and cucumbers are “fruits” rather than “vegetables”.
- Unit tests deliberately introduce API rigidity; you cannot change the API without changing the tests, and rightly so! So if your API embodies a larger principle that would be true of all possible APIs, you might want an integration test instead.
- Integration tests test that large sections of the code, like entire
libraries, work together to accomplish caller-relevant tasks.
- Integration tests are the tests that stay mostly the same when you refactor a module: Refactoring often changes lower-level APIs, but the same overall narrative purpose remains.
- A common informal distinction is that unit tests complete in less than a second on most platforms; anything bigger than that needs a higher level test because you’re likely going to end up refactoring it for performance later.
- System tests invoke user-level affordances like binaries under realistic
or simulated conditions as though a user were carrying out a supported
action.
- A common informal rule is that system tests may be too long to run in pre-merge CI, or may run only on specific platforms; this should not be true of integration tests which should remain a part of developers' daily workflows.
I know my tests, but I’m less familiar with Rust’s conventions around them. Here’s my best first pass at how Rust does this, and how we’ll use it.
Unit tests and integration tests
Cargo’s idiosyncratic convention is that unit tests live near code, while
integration tests live parallel to code. That is, you can put your module
unit tests right in the same file as your module, or nextdoor. Tests that
test multiple modules or entire libraries or binaries, though, live in a
tests directory sibling to src.
(Test helper tools conventionally live in modules beneath a tests directory
to prevent them being autodiscovered as tests; this is a rather dubious layout
that doesn’t help with unit test helpers, so we’ll ignore this for now.)
System tests
System tests are a different beast; because they simulate user behavior rather than going through your module APIs, they exist at a fundamentally different level than our source code. This is why many large low-level codebases have system tests written in python, shell scripting, or even perl for their binary artifacts.
Higher-level languages like python are particularly good for system testing because of their fluent syntax for text manipulation.
Cargo doesn’t provide hooks for system testing, because that isn’t its job –
system tests exist above built artifacts. There are several cargo modules
to allow higher-level scripting (cargo-run-script is notable here) but we
will follow Rico’s Law here and use a scripting language
rather than embed scripting in a config language.
Special case: Testing main
main is a function, and therefore an API subject to testing. It
by definition has behavior that changes during development (at some level
of generality all feature development exists principally to change the
behavior of main), so we’ll call that an integration test.
An understandable gap in Rust’s test framework is that main.rs is the one
file that cannot be tested from within it.
As such we have an obligation to make main vacuous of all nontrivial logic.
That is done by moving the interesting content into a lib.rs file.
This PR
Cargo’s hello-world setup only gave us a main.rs, no modules, so there’s
no place for unit tests so far. So we’ll start off with an integration test,
just to pave the ground a little bit. Since main.rs currently just does a
“Hello, world!”, that’s what we’ll test for.
So this PR adds:
- Indirection of
mainto make it unit-testable, - An example unit test of the main function,
- An example integration test of the main function, and
- An example system test of the main binary target.
After this PR:
cargo checkpasses (our build configuration is sound)cargo clippypasses (we are lint-free)cargo testpasses (our units and integration points are sound)./tests/system_smoke_test.pypasses (our sole system test passes)
None of this is of any real significance; it’s just laying out some working infrastructure. We’re still a couple of PRs away from “real” code, but a sound foundation pays for itself.
This blog post corresponds to repository state post_03
Lunar metadata: This is a contraction phase; the density of the codebase grows.
First things first
Before we do anything else, we start a repository. Nothing fancy, I’ll use some default github presets, along with my standard bits and pieces.
A lawyer once told me that Apache 2 is the sensible default license so we’ll start with that. I’ll be the only contributor to this repository, and I can freely relicense in the future as long as that’s the case.
I think everyone who’s been in the game for a while has their own standard starting repository configuration. I try to hew pretty closely to the “happy path” of my tools, since it’s easier to refactor away from the happy path than to start there and try to get back.
The first choice in any project is the language, which is closely tied to the second question, whether to work top-down or bottom-up. I’m a bottom-up guy, and the legitimate hotness for low-level systems programming these days is Rust. I don’t know Rust very well, I’ve written maybe a couple of thousands of lines total, but most programming languages are similar enough that after your first twenty or thirty they start to rhyme nicely.
Rust provides a project source and build manager called cargo, and I’ll use
that to set up the world.
cargo init .
Cargo sets this up as a binary project; that might or might not be right for us; we’ll see as we go.
Cargo follows the convention that a project starts in a src directory.
That’s not my usual style, but we’ll roll with it while we get our bearings.
This blog post corresponds to repository state post_02
Lunar metadata: This is an expansion phase; the scope of the codebase grows.
Let's Make a Database
Call me Barzai (my IRL name is easily found, but we’re internet friends so let’s use internet names; if you are polite you will refrain from doxing). I’m a software engineer, classically trained, and have decided to spread some experience.
I’m doing this for a few reasons, both altruistic and selfish, public and private. But the big one is:
- There are a lot more people who need to know practical systems engineering than are teaching it,
- The quality of online tutorial resources that are narrative (not just complete projects) and project-sized (neither just two or three files nor impossibly huge) is very poor, and
- When people are bad at this, the costs of their unskillful work fall on others, including sometimes on me.
So we’re going to make a database.
This isn’t going to be a big fancy SQL monster like Oracle, or even something comparable to open-source databases like MySQL or Postgres. This is going to be something small and a little bit silly. But it’s going to show you some of the things that I’ve learned in my decades as a software engineer that might help you brush up your systems engineering chops, or just be a fun romp through some styles of code that most people don’t get to play with.
On the way we might hit networking, parsing, language design, test methodology, polyglot codebases, performance optimization, design philosophy, and a million other things. I think it will be fun!
Here are some ground rules:
- I’m using free tools where practical. It should be possible to reproduce
this work without spending more than a few dollars – none at all, if
possible – because this is educational material and if cost is a barrier
to education then we are all worse off in the end.
- Of course cost should not be a barrier to most anyone in a position to use this tutorial, but “should” and $5 buys a mediocre coffee these days.
- Conversely, none of the “free tools” are really quite free. If you gain profit by a free tool, it would be proper to donate a bit to the maintainers, wouldn’t it?
- I’m deliberately choosing an unfamiliar language. I’ll be using Rust for
this project, even though my own background is C, C++, and python (and
Java. And Haskell. And XQuery. And…).
- This is because stumbling through bad code and unfamiliar toolchains is a core part of systems engineering. If I were working in C++ this would be too easy for me and I would unconsciously gloss over details.
- If you say “I am uncomfortable writing code in an unfamiliar language” then this is the wrong level for you. In my view, mature systems programming begins where programming languages start to blur together, which for most people seems to be after 8-10 years of full-time software work in three different languages.
- I’m going to call my shots – I will make design decisions and choices of tools explicitly. This will force me to make some of my implicit knowledge explicit.
- This will be narrative – it will consists of reasonably PR-sized chunks,
interspersed in places with amusing stories, as one would experience the
growth of such a codebase over time.
- Concretely, each post here will correspond to a git revision. It will be possible to see the state of the code “at the time of” the relevant design decision.
- This will be subjective – I have a point of view and an attitude, solecisms and idiosyncrasies, ethics and outright curmudgeonly antique habits of thought and action; I hope that by making my own point of view clear, you can see how you might make your own personal style an asset in your own development.
- This will have approximately weekly posts describing an approximately
daily pace – each post will resemble a day’s work for a mature (not
super-high velocity) developer. An old rule of thumb states that a
developer can average fifty correct lines of code per day.
- There will be posts here with more that fifty lines – sometimes considerably more. Those will contain correspondingly many defective lines of code.
- There will be posts here with zero lines – design days, watercooler storytelling days, and so forth.
- There will be sarcasm and swearing. If you don’t associate software engineering with sarcasm and swearing, you probably aren’t quite the target audience; come back in a couple of years when your mental health is worse.
If you agree, let’s begin…
This blog post corresponds to repository state post_01